
Decision makers — organizational leaders, fiscal sponsors, policymakers — are often in the position of deciding the fate of a pilot program that has "failed" in its evaluation. This isn’t an easy charge. In many contexts, it can seem safest to stick to the p<0.05 rule and make decisions based primarily on statistical significance of the primary outcome. But in practice, decisions are more complicated than this. So how should leaders in the complex care community be thinking about evaluation findings, rigor, and implementation or de-implementation decisions? And how might we think more carefully about what it means when evaluation findings are null?
Rigorous Evaluation: Promise and Pitfalls
A growing number of complex care interventions are being evaluated using rigorous designs like the randomized controlled trial (RCT). This has been a long time coming and will contribute to the growth of the complex care field. In addition to being necessary for identifying effective practices (and not falsely propagating ineffective ones), engaging in rigorous evaluation brings credibility to the field.
However, lore in the evaluation community is that the worst thing you can do for a promising intervention is to evaluate it via an RCT too soon. One reason is that rushing to a randomized evaluation can result in an underpowered trial — one without sufficient statistical power to detect a program effect whether or not an effect is there. Some might even argue that an underpowered trial is worse than no trial at all, because an underpowered trial might condemn a good intervention based on a misinterpretation of a null result. It’s easy to forget that a null result means only that we were not able to prove an effect; it is not evidence of ineffectiveness.
Why Should Decision Makers Care about Statistical Power?
Underpowered trials are a problem for everyone: patients contribute data to a study that yields few useful findings. Funders and innovators waste time and money. Credibility of a potentially effective intervention is damaged. Nevertheless, underpowered trials are commonplace in the care innovation world, because care innovation trials are not like the classical pharma trials where RCT methods were built. These are complex, multifaceted, and prolonged interventions that are difficult to deliver with fidelity. They are often implemented within the context of usual care, and trial design choices that make implementation easier can inadvertently chip away at statistical power.
Power is often thought about in terms of sample size, and it is true that many complex care pilot studies have limited time and resources to enroll participants. But statistical power is a nuanced concept that is also related to choices around study design, outcome measures, population, and trial procedures. Poorly executed power analyses can be a root cause of underpowered studies. Even in a study designed to have adequate power at the outset (Figure 1), difficulties in enrollment processes and intervention delivery can lead to a substantial loss of power.
Figure 1. Loss of Statistical Power in Real-World Trials of New Care Models
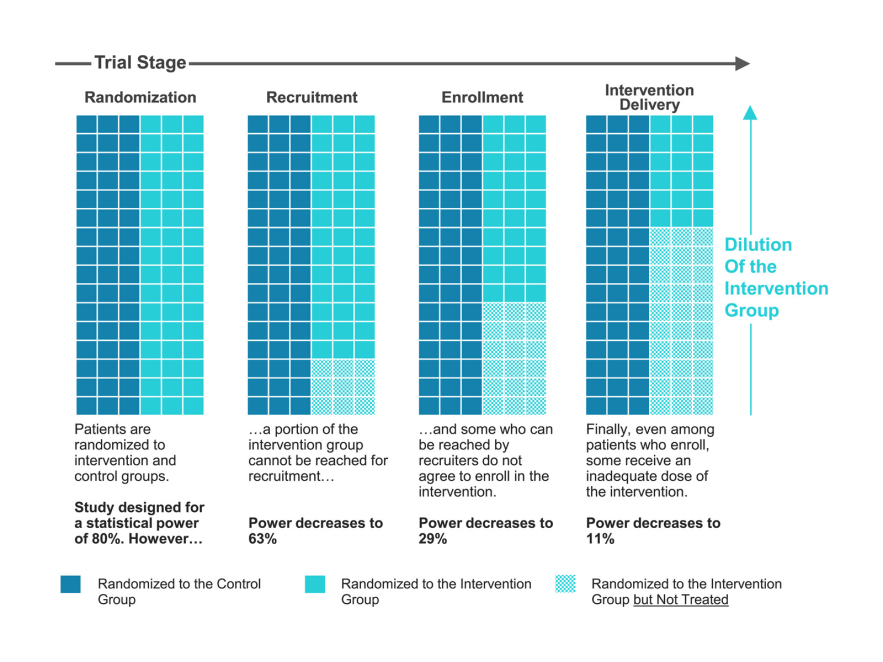
Source: Davis AC, Adams JL, McGlynn EA, Schneider EC. Speaking truth about power: Are underpowered trials undercutting evaluation of new care models?. Journal of Evaluation in Clinical Practice. 2023 Jul 12.
It can be tempting to not take power analysis seriously enough, and when reviewing a study plan for a care innovation trial, special attention should be paid to the assumptions inherent in the power calculation about recruitment, enrollment, and intervention delivery. While hiccups in trial implementation can undermine planned power, a thoughtful power analysis can account for these issues (or highlight the need for some rethinking of trial design to avoid them all together).
The Power of Bending Evaluation Orthodoxy in Complex Care
The primary analysis of any trial — the intent to treat analysis — is the most unbiased estimate because participants are analyzed as randomized to ensure equivalence between the study groups. In evaluation orthodoxy, the intent to treat analysis is the only analysis for a variety of good reasons. Foremost, there is reason to worry about undisciplined data mining within a null trial. It can feel tempting to explore sub-group analyses that focus on patients who received the full treatment protocol, but it is well known that patients who take the treatment differ from those who don’t in ways that cannot usually be measured. This means that any analyses that break the randomization schema are suspect, and a stringent evaluation approach may discourage even exploring them because of fear of over-claims based on the findings.
However, decision makers should know that the intent to treat analysis yields an estimate of the effect of treatment assignment, represented as an average treatment effect. In a tightly implemented trial with very high fidelity (like a typical pharma trial), treatment assignment consistently leads to treatment receipt and this average just reflects the inherent heterogeneity that is found in a population of individuals receiving the same intervention. The effect of treatment assignment and the effect of treatment receipt are one and the same.
Now consider a scenario like Figure 1: in a trial where only a portion of the intervention group receives any treatment at all, the intent to treat estimate averages over not only the heterogeneity of treatment effects among the treated, but also over the impossibility of a treatment effect among the untreated. In a sense, the intent to treat estimate in this case is watered down.
In a scenario when an intervention was incompletely delivered and the trial was consequentially underpowered, we believe that bending evaluation orthodoxy can be sensible for the field of complex care. Afterall, we wouldn’t call a pill ineffective if we learned that the mail truck responsible for delivering it had broken down. There are methods for disciplined secondary analyses that further explore variation in effectiveness within the trial population. Instrumental Variables Analysis, the Complier Average Causal Effect (the related Local Average Treatment Effect), and the Distillation Method are all reasonable options. These secondary analysis strategies can inform decision makers by digging into a null finding and understanding how effectiveness varied within the treatment group.
We recently collaborated on a re-analysis of the widely read Camden Coalition of Health Care Providers’ Hotspotting Trial, which was null for its primary outcome in the original intent to treat analysis. Borne out of the observation that a substantial portion of the trial population received few intervention services, we used the Distillation Method to explore the role of intervention engagement on readmission outcomes. When we focused analysis on those most likely to engage with the intervention, we found a signal that there likely was an intervention effective for a portion of the targeted population.
Even in a trial that shows a statistically significant effect, when there is variability in intervention receipt (dose, duration, or whatever concept is relevant in a given case) it may be useful to decision makers to explore variation in treatment effect. Perhaps an intervention with a significant effect averaged over the whole treatment group could be targeted to a subset of the original population where the treatment effect was even greater.
Closing
The result of the intent to treat analysis is almost never the entirety of the decision-making process. Other factors will always weigh in implementation and de-implementation decisions: clinical reasoning, patient and staff experience, leadership buy-in, and charisma of the innovator are a few of these factors. This is true regardless of whether trial results are statistically significant or null.
When a study was ultimately underpowered to detect intervention effects — either from the outset or due to implementation issues that disrupted intervention delivery — the decision landscape requires extra care. Looking more deeply at the results of an underpowered trial using disciplined secondary analysis methods can yield signals that are useful to inform a redesign and retrial of the intervention, to re-shape eligibility criteria, or to increase confidence in decision making without a new trial.
If we implement underpowered trials and evaluate them using only standard intent to treat methods, we risk tossing out potentially effective interventions and we slow the pace of learning in this field. Innovators, funders, and decision makers can all play a role in thinking more carefully about the meaning of null results, especially when they arise from a trial that was underpowered.
* The opinions expressed within this article are solely the authors’ and do not reflect the opinions and beliefs of Kaiser Permanente or its affiliates.